La recherche d’information m’a toujours passionné : qu’il s’agisse de feuilleter des livres de disciplines variées, passer des heures sur les résultats des moteurs de recherches ou explorer les larges bases de données d’entreprises (informatique décisionnelle), j’ai toujours pris du plaisir surtout quand qu’il s’agit de prise de décision.
En effet, toute prise de décision est basée sur l’information dont on dispose en date et lieu. Dans le cas d’une décision d’achat: on pourra se baser sur notre expérience de consommateur, l’avis des personnes qui nous entourent, les médias institutionnels et les avis de consommateurs en ligne. Il faut noter que davantage d’internautes (moi même d’ailleurs) accordent de plus en plus du crédit aux avis de consommateurs. Tout l’enjeu de la recherche d’information est de trouver la « bonne information » dans un temps record.
La recherche d’information décortiquée
Dans l’ère du web social, pour moi, la Recherche d’information = « Recherche de documents » + « Recherche de conversations » + « Recherche d’entités/personnes »

Recherche de documents
Un document est toute ressource (texte, son, image, vidéo) disponible dans les sites institutionnels, pages web personnels, blogs et autres interfaces web. La communication d’information par le biais de documents correspond à un modèle de communication unidirectionnel : émetteur —> récepteur. A travers le document, l’auteur s’adresse à la foule sans que la foule puisse répondre. Le web social verra l’avènement des conversations où la communication d’information est bidirectionnelle : émetteur <—> récepteur, voire (n) émetteurs <–> (n) récepteurs
La collecte et indexation de documents disponibles en ligne a été le leitmotiv des premiers moteurs de recherche. D’ailleurs, Google est issu du projet Stanford digital library. La plupart des moteurs fonctionnent ainsi : collecte de documents (crawl), indexation et réponse aux requêtes des utilisateurs.

Le schéma ci-dessous est issu d’une excellente thèse doctorale réalisée en 2004 par Carlos Castillo sur la collecte d’informations, intitulée Effective Web Crawling, disponible en téléchargement libre. Pour en savoir plus, je vous recommande également le billet de Frédéric Martinet à ce sujet.
Recherche de conversations
Les conversations entre humains regorgent souvent d’informations qu’on retrouvera difficilement dans les documents. En cherchant sur un moteur de recherche de documents, il est difficile de trouver des avis sur les restaurants du quartier, le coiffeur ou le boucher du coin.
Comment alors trouver la ou les ‘bonnes conversations’ qui répondent à notre besoin d’information ? Généralement, la formulation de notre demande d’avis auprès de proches ou de collègues se fait en langage naturel (langage parlé). Aussi, notre acceptation de leurs réponses est basé sur notre intimité avec la personne qui apporte l’information et/ou son niveau de connaissance du sujet.
Dans notre ère du web social, notre cercle de connaissances est étendu aux personnes auxquelles nous sommes connectés en ligne, voir toutes les personnes dotées d’une identité numérique. Dans ce cas, à qui s’adresser pour avoir une réponse à nos questions ?
C’est le leitmotiv des moteurs de recherches sociaux précurseurs du domaine dont Aardvark. L’équipe de ce dernier a produit un article très intéressant à l’occasion du WWW 2010 où elle aborde son approche de la recherche de documents et de conversations : The library and The village paradigms
Traditionally, the basic paradigm in information retrieval has been the library. Indeed, the field of IR has roots in the library sciences, and Google itself came out of the Stanford Digital Library project. [….] In a village, knowledge dissemination is achieved socially — information is passed from person to person, and the retrieval task consists of finding the right person, rather than the right document, to answer your question.
[…] In a library, people use keywords to search, the knowledge base is created by a small number of content publishers before the questions are asked, and trust is based on authority. In a village, by contrast, people use natural language to ask questions, answers are generated in real-time by anyone in the community, and trust is based on intimacy. These properties have cascading effects — for example, real-time responses from socially proximal responders tend to elicit (and work well for) highly contextualized and subjective queries. For example, the query “Do you have any good babysitter recommendations in Palo Alto for my 6-year-old twins? I’m looking for somebody that won’t let them watch TV.” is better answered by a friend than the library. […]
The fact that the library and the village paradigms of knowledge acquisition complement one another nicely in the offline world suggests a broad opportunity on the web for social information retrieval.
Ci-dessous un aperçu de l’architecture applicative d’Aardvark, issu du même papier que j’ai référencé avant :

Recherche d’entités/personnes
Depuis sa création, le web a évolué d’un espace centré sur les documents vers un un web centré sur les individus et entités. Un article écrit par TechCrunch ou Mashable, sur une thématique donnée, « vaut » mieux qu’un article écrit par un magazine moins connu ou un blogueur lambda. La valeur de l’article étant mesurée en fonction de la source, le nombre de visites, commentaires, tweets, partage sur Facebook, Digg, Delicious….
Pour se retrouver dans le volume gigantesque des flux d’informations (documents + conversations), on s’appuiera davantage (nous individus et moteurs de recherche) sur la source de l’information. Chaque source (entité/personne) étant dotée d’une certaine notoriété, image en ligne et degré d’ « influence ».
Twitter suggère de suivre des personnes en proposant des thématiques (Actualités, Art, Mode & Design, Caritatif..). La même fonctionnalité est présente également dans certains réseaux sociaux, plateformes de blogs et bookmarks. La recherche de personnes se base majoritairement sur des tags et analyse du contenu (local au service).

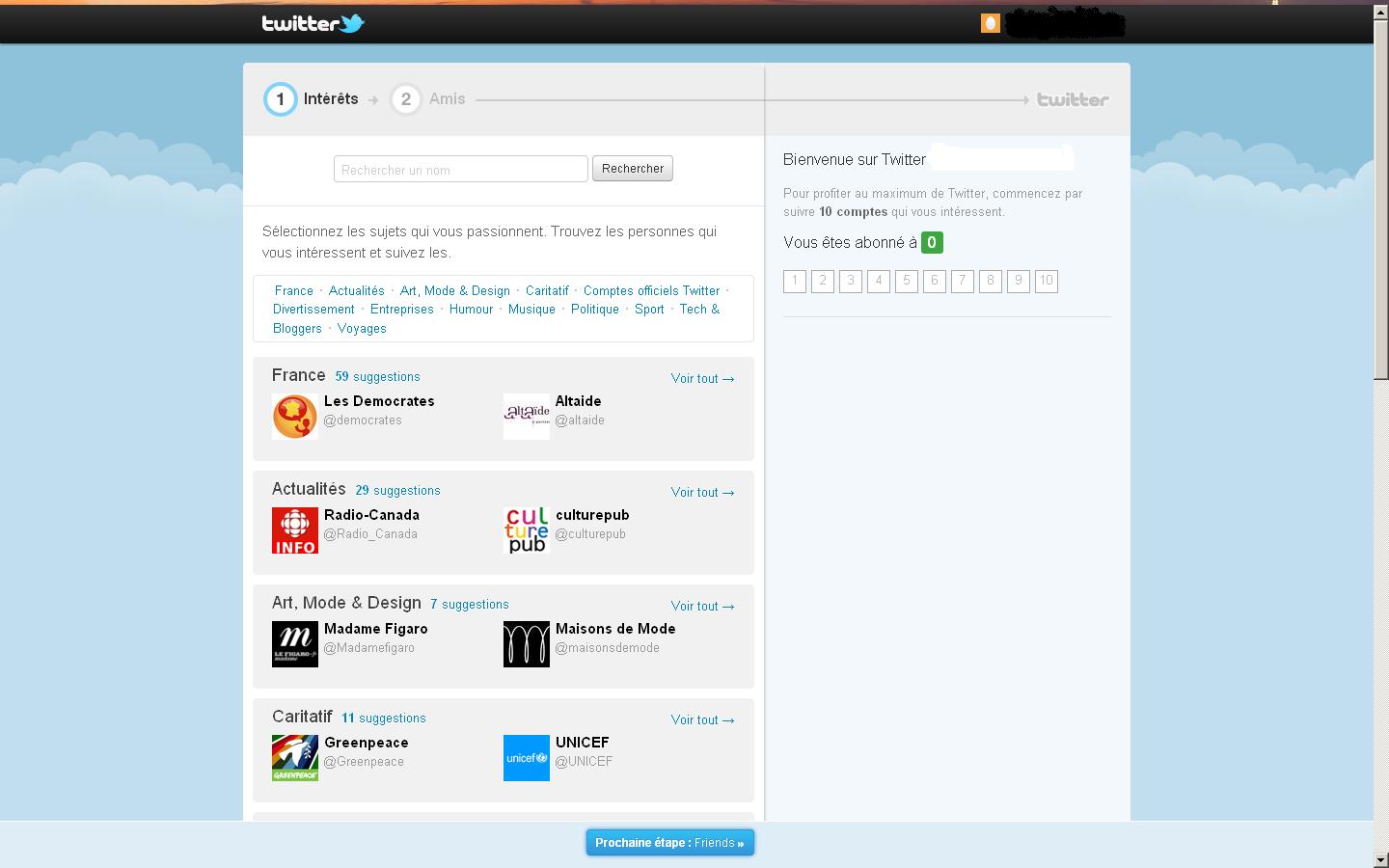{kind=link}
L’avenir de la recherche de personnes est de disposer de services web capables de proposer une liste de personnes par thématique donnée, en se basant sur l’ensemble des informations disponibles en ligne. Peut être bien qu’un tel service existe, j’en ignore l’existence alors !
Quelques mots sur le futur
La recherche d’informations a encore de beaux jours devant elle, et des challenges à relever :
- Recherche de documents : analyse du son – reconnaissance vocale – structure d’image/recherche d’image similaire
- Recherche de conversations : un meilleur traitement du texte (requêtes en langage naturel, textes de conversations)
- Recherche de Personnes : approche scientifique de la notion d’influence, cartographie automatique des réseaux de personnes (indépendamment des réseaux sociaux)
Là j’ai fini :). A vous de me dire : qu’est ce que vous en dites de la recherche d’information à l’ère du web social ?
Crédit image de garde : http://memsic.ccsd.cnrs.fr/docs/00/33/48/47/HTML/bAnnexes_isabellequillien/base_fichiers/image013.jpg
Pingback: Tweets that mention La recherche d’information à l’ère du web social | Digital Reputation Blog -- Topsy.com
Bonjour Amine,
Merci pour cet article où je trouve des références très utiles.
Pour info et comme le sujet du social search t’intéresse, je te conseille de jeter un oeil à celles que je cite dans ce papier : http://bit.ly/b6kkVB
Bonjour Christophe,
Merci pour ton commentaire et pour le lien. J’ai déjà téléchargé ton article que j’ai lu en diagonale.
Je vais prendre le temps de le lire en entier. Je n’ai aucun doute qu’il me sera aussi utile, pour mes travaux sur la recherche d’informations.
Bonjour Amine,
En fait, plus que mon article en soi ce sont les références aux travaux de Morris, Evans et Chi qui pourront, je pense, t’intéresser.
Article très intéressant, un sujet passionnant en effet!
Pingback: Digital Reputation Blog » Tendances de la veille sur les médias sociaux 2011/2012